【读书笔记】《程序员的自我修养:链接、装载与库》
on 技术笔记
目录
第1部分 简介
1.1 计算机系统
硬件部分
- 对于系统程序开发者来说,计算机多如牛毛的硬件设备中,有三个部件最为关键,它们分别是中央处理器CPU、内存和I/O控制芯片
- 北桥连接所有高速芯片,南桥连接所有低速芯片
- 北桥采用过的总线结构有PCI、AGP或PCI Express等
- 除非想把CPU的每一滴油水都榨干,否则可以把多核处理器和对称多处理器(SMP)看成同一个概念
软件部分
系统软件
- P.8 “计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决”
- 每个层次之间都需要相互通信,既然需要通信就必须有一个通信的协议,我们一般将其称为接口(Interface)
- 应用程序编程接口(Application Programming Interface)
- 运行库使用操作系统提供的系统调用接口(System Call Interface)
- 系统调用接口在实现中往往以软件中断(Software Interrupt)的方式提供
操作系统
- 充分挖掘CPU潜力
- 早期:多道程序的方法–监控程序监控CPU资源
- 协作的模式:分时系统
- 现代:多任务系统–所有应用程序都以进程的方式运行在比操作系统权限更低的级别,CPU分配方式为抢占式(Preemptive)
- I/O设备
- 硬件管理交给硬件驱动程序(Device Driver)来完成
- UNIX系统中,硬件设备的访问形式跟访问普通的文件形式一样
- Windows系统中,图形硬件被抽象成了GDI,声音和多媒体设备被抽象成了DirectX对象,磁盘被抽象成了普通文件系统
- 文件系统:硬盘基本存储单位为扇区(Sector),向硬盘发送I/O命令的方式有很多种,其中最为常见的一种就是通过读写I/O端口寄存器来实现
- 内存
- 在早期的计算机中,程序是直接运行在物理内存上的。在将有限的物理内存分配给多个程序使用时,会带来三个问题:1. 地址空间不隔离 2. 内存使用效率低 3. 程序运行的地址不确定(涉及重定位的问题)
- 解决问题的思路是增加中间层:将程序给出的地址看作是虚拟地址(Virtual Address),然后映射到物理地址
- 分段(Segmentation):采用段映射机制,将程序所需的虚拟内存空间整段映射到物理内存空间
- 分页(Paging):分页的基本方法是把地址空间人为地等分成固定大小的页,目前几乎所有PC上的操作系统都使用4KB大小的页
- 虚拟页(VP, Virtual Page),物理页(PP, Physical Page),磁盘页(DP, Disk Page)
- 可以通过内存共享机制解决内存使用效率低的问题
- 保护也是页映射的目的之一,简单地说就是每个页可以设置权限属性,只有操作系统有权限修改这些属性
- 虚拟存储的实现需要依靠硬件的支持,几乎所有CPU都采用MMU(Memory Management Unit)将虚拟地址转换成物理地址
多线程
- 线程的概念
- 线程是程序执行的最小单元
- 一个标准的线程由线程ID、当前指令指针(PC)、寄存器集合和堆栈组成
- 各个线程之间共享程序的内存空间(包括代码段、数据段、堆等)及一些进程级的资源(如打开文件和信号)
- Windows对进程和线程的实现如同教科书一般标准,而Linux对多线程的支持颇为贫乏
- 线程的访问权限
- 线程的私有存储空间包括以下几个方面
- 栈(尽管并非完全无法被其他线程访问,但一般情况下仍然可以认为是私有的数据)
- 线程局部存储(Thread Local Storage)
- 寄存器(包括PC寄存器)
- 从C程序员的角度来看,数据在线程之间是否私有如表1-1所示

- 线程的私有存储空间包括以下几个方面
- 线程调度与优先级
- 不断在处理器上切换不同的线程的行为称之为线程调度(Thread Schedule)
- 在线程调度中,线程通常至少有三种状态:运行、就绪、等待
- 处于运行中线程拥有一段可以执行的时间,这段时间称为时间片(Time Slice)
- 线程调度有不同的方案和算法,现在主流的方法都带有优先级调度(Priority Schedule)和轮转法(Round Robin)的痕迹
- IO密集型线程:频繁等待的线程;CPU密集型线程:很少等待的线程
- 可抢占线程和不可抢占线程:线程在用尽时间片后被强制剥夺继续执行的权力,这个过程叫做抢占(Preemption)
- 线程安全
- 原子操作:编译成汇编代码之后单指令的操作称为原子(Atomic)操作
- 同步:在一个线程访问数据未结束的时候,其他线程不得对同一个数据进行访问
- 同步的最常见方法是使用锁
- 二元信号量(Binary Semaphore)是最简单的一种锁,它只有两种状态:占用和非占用
- 多元信号量:一个初始值为N的信号量允许N个线程并发访问
- 互斥量(Mutex)和二元信号量类似,但是互斥量只允许获取它的线程释放它
- 临界区(Critical Section)是比互斥量更加严格的同步手段,它只在本进程可见;互斥量和信号量在其他进程也是可见的
- 读写锁(Read-Write Lock):对于读取频繁而仅仅偶尔写入数据的情况,读写锁更加高效
- 条件变量(Condition Variable):使用条件变量可以让许多线程一起等待某个事件的发生,当事件发生时,所有的线程可以一起恢复执行
- 可重入(Reentrant)与线程安全
- 一个函数要被重入,只有两种情况:1. 多个线程同时执行这个函数 2. 函数自身(可能是经过多层调用之后)调用自身
- 可重入的函数具备的特点:P. 28
- 过度优化
- 编译器做的过度优化可能会导致线程不安全:第一个问题是编译器为了提高速度将一个变量缓存到寄存器内而不写回,第二个问题是编译器可能为了效率交换毫不相干的两条相邻指令的执行顺序
- 使用volatile关键字可以完美解决第一个问题
- CPU的乱序执行能力让我们对多线程安全的努力变得异常困难,然而现在并不存在可移植的阻止换序的方法,可以尝试使用barrier
- 多线程的内部实现
- 一对一模型:一个用户线程唯一对应一个内核线程
- 多对一模型:将多个用户线程映射到一个内核线程上
- 多对多模型:将多个用户线程映射到少数但不止一个内核线程上
第2部分 静态链接
2.1 编译和链接
程序构建(Build)
- 通常将编译和链接一步完成的过程称为构建(Build)
- 构建过程可以分解为4个步骤,分别是预编译、编译、汇编和链接
- 预编译
$ gcc -E hello.c -o hello.i- 处理以“#”开始的预编译指令和宏
- 编译
- 编译过程就是把预处理完的文件进行一系列词法分析、语法分析、语义分析及优化后生成相应的汇编代码文件
$ gcc -S hello.i -o hello.s或者$ /usr/lib/gcc/[PATH]/cc1 hello.c- gcc进行预编译和编译实际上是调用的后台预编译编译程序来执行,对C语言来说是cc1,C++是cc1plus,Objective-C是cc1obj,fortran是f771,Java是jc1
- 汇编
- 调用汇编器来完成:
$ as hello.s -o hello.o - 或者
$ gcc -c hello.s -o hello.o
- 调用汇编器来完成:
- 链接
- 使用链接器
ld
- 使用链接器
编译步骤
- 编译过程一般可以分为6步:词法分析、语法分析、语义分析、源代码优化、代码生成和目标代码优化
- 词法分析将源代码的字符分割成一系列的记号(Token)
- 扫描器运用一种类似于有限状态机的算法进行词法分析,程序
lex是一个扫描器
- 扫描器运用一种类似于有限状态机的算法进行词法分析,程序
- 语法分析器对由扫描器产生的记号进行语法分析,从而产生语法树
- 采用了上下文无关语法(Context-free Grammar),生成以表达式为节点的树
- 语法分析有一个现成的工具叫做yacc(Yet Another Compiler Compiler)
- 语义分析器分析语法树的表达式是否合法
- 编译器能分析的是静态语义,即在编译期可以确定的语义
- 静态语义通常包括声明和类型的匹配,类型的转换
- 动态语义是在运行期才能确定的语义,比如将0作为除数
- 中间语言生成
- 源代码级优化器在源代码级别进行优化,将语法树转换成中间代码
- 中间代码有很多种类型,常见的有三地址码和P-代码
- 最基本的三地址码是这样的:x = y op z
- 中间代码使得编译器可以被分为前端和后端。编译器前端负责产生机器无关的中间代码,编译器后端将中间代码转换成目标机器代码
- 目标代码生成与优化
- 代码生成器将中间代码转换成目标机器代码
- 目标代码优化器对目标代码进行优化,比如选择合适的寻址方式、使用位移来代替乘法运算、删除多余的指令等
链接器
- 程序修改时重新计算各个目标的地址过程被叫做重定位(Relocation)
- 符号(Symbol)这个概念随着汇编语言的普及迅速被使用,它用来表示一个地址,这个地址可能是一段子程序的起始地址,也可以是一个变量的起始地址
- 程序模块间会有符号引用,将模块拼接的过程称之为链接(Linking)
- 链接过程主要包括了地址和空间分配(Address and Storage Allocation)、符号决议(Symbol Resolution)和重定位(Relocation)等步骤
- 目标文件和库一起链接形成最终可执行文件,最常见的库就是运行时库(Runtime Library)
- 地址修正的过程叫做重定位,每个要被修正的地方叫一个重定位入口
2.2 目标文件
无论是可执行文件、目标文件或库,它们实际上都是一种基于段的文件或是这种文件的集合。(P. 95)
目标文件格式
- 动态链接库及静态链接库文件都按照可执行文件格式存储
- 现在PC平台流行的可执行文件存储格式主要是Windows下的PE(Portable Executable)和Linux的ELF(Exectuable Linkable Format),它们都是COFF(Common file format)格式的变种
- ELF标准将ELF文件归为以下4类
- 可重定位文件(Relocatable File):如Linux的.o,Windows的.obj
- 可执行文件(Executable File):如/bin/bash,Windows的.exe
- 共享目标文件(Shared Object File):如Linux的.so,Windows的DLL
- 核心转储文件(Core Dump File):如Linux下的core dump
- 我们可以在Linux下使用
file命令查看相应的文件格式
目标文件结构
- 目标文件一般包含文件头、代码段、数据段、BSS段等
- 程序指令(代码段)和程序数据(数据段、BSS段)分开的好处:(1)读写权限 (2)提高CPU缓存命中率 (3)指令共享内存
objdump可以用于查看各种目标文件结构和内容$ objdump -h hello.o查看目标文件头的信息- .text是代码段,.data是数据段,.bss是BSS段,.rodata是只读数据段,.comment是注释信息段,.note.GNU-stack是堆栈提示段
- 代码段
$ objdump -s hello.o将所有段以十六进制打印出来$ objdump -d hello.o反汇编可执行段
- 数据段和只读数据段
- .data段存放已经初始化了的全局静态变量和局部静态变量
- .rodata段存放只读数据,一般是只读变量(如const变量)
- BSS段存放未初始化的全局变量和静态变量
- 其他段参考书中表3-2
size指令可以用于查看ELF文件各个段的长度
ELF文件结构
- 文件头
- 可以通过
$ readelf -h hello.o查看 - 各字段的含义可以参考表3-3、3-4、3-5和3-6
- 可以通过
- 段表
objdump -h只把关键的段显示了出来,省略了辅助性的段$ readelf -S hello.o显示的才是真正的段表的结构- 各字段含义参考表3-7到表3-11
- 重定位表
- 字符串表
- .strtab是字符串表,用来保存普通的字符串
- .shstrtab是段字符串表,用来保存段表中用到的字符串,最常见的就是段名
- 符号表
- 在链接中,我们将函数和变量统称为符号(Symbol),函数名或变量名就是符号名
- readelf、objdump、nm等工具可以用来查看符号表
- ELF文件中的符号表往往是文件中的一个段,段名一般叫.symtab
$ readelf -s hello.o
- 调试表
- GCC编译时加上-g参数会在目标文件中有调试信息
- 在Linux下,可以用strip命令去掉ELF文件中的调试信息
$ strip foo
链接的接口–符号
- 特殊符号
- ld链接生成可执行文件时会为我们定义很多特殊符号
- 符号修饰与函数命名
- C++通过命名空间来解决符号冲突的问题
- 符号修饰:
c++filt可以用来解析修饰后名称
extern "C"- 在C++中声明或定义一个C的符号
#ifdef __cplusplus配合使用
- 弱符号与强符号
- 对于C/C++来说,编译器默认函数和初始化了的全局变量为强符号,未初始化的全局变量为弱符号
- 我们也可以通过GCC的
__attribute__((weak))来定义一个强符号为弱符号 - 强符号和弱符号都是针对定义的概念,而不是针对引用
- 强符号不能被多次定义,弱符号可以
- 【弱引用与强引用】
- 在处理强引用时,如果没有找到该符号的定义,链接器会报符号未定义错误
- 在处理弱引用时,如果符号有定义,则链接器将该符号的引用决议;如果符号未被定义,链接器对于该引用也不报错
- 一般对于未定义的弱引用,链接器默认其为0,或者是一个特殊的值
- GCC中,弱引用关键字为
__attribute__((weakref)) - 弱符号和弱引用对于库来说十分有用,比如
- 库中定义的弱符号可以被用户定义的强符号覆盖
- 将某些扩展功能模块定义为弱引用,使得无论有没有这个模块都能正常链接
- 程序既支持单线程也支持多线程使用时
2.3 静态链接
空间与地址分配
- 可执行文件中的代码段和数据段都是由输入的目标文件中合并而来的
- 空间分配方案:这里的空间分配只关注于虚拟地址空间的分配
- 按序叠加
- 相似段合并(现在的链接器基本都采用这种方案)
- 两步链接(Two-pass Linking)法:第一步、空间与地址分配,第二步、符号解析与定位
$ ld a.o b.o -e main -o ab,其中-e main表示将main函数作为程序入口
符号解析与重定位
- 重定位表:用来保存与重定位相关的信息
$ objdump -r a.o可以用来查看目标文件的重定位表
- 符号解析
$ readelf -s a.o可以查看目标文件的符号表
- 指令修正方式
- 近址寻址或远址寻址
- 绝对寻址或相对寻址
- 寻址长度为8位、16位、32位或64位
- COMMON块
- 链接器需要处理两个或两个以上弱符号类型不一致的情况
- 编译器和链接器都支持一种叫COMMON块的机制来解决这个问题
- gcc的
-fno-common允许我们把所有未初始化的全局变量不以COMMON块的形式处理,或者使用__attribute__扩展int global __attribute__((nocommon)) var;
- 链接器需要处理两个或两个以上弱符号类型不一致的情况
C++相关问题
- 重复代码消除
- C++编译器在很多时候会产生重复的代码:比如模板、外部内联函数和虚函数表等
- 模板:GCC的处理方式是将这种段命名为
.gnu.linkonce.name,Visual C++编译器将这种段叫做COMDAT - 虚函数:虑函数表(Virtual FunctionTable,一般简称为vtbl)
- 外部内联函数、默认构造函数、默认拷贝函数和赋值操作符也有类似问题
- 模板:GCC的处理方式是将这种段命名为
- 函数级别链接
- 前面的普通链接方式将没有用到的函数也一起链接了进来
- Visual C++和GCC都提供了函数级别链接
- GCC的编译选项分别是
-ffunction-sections和-fdata-sections
- C++编译器在很多时候会产生重复的代码:比如模板、外部内联函数和虚函数表等
- 全局构造与析构
- “.init”段里保存着进程的初始化代码指令,在main函数执行前系统就会执行它
- “.fini”段里保存着进程的终止代码指令,在main函数返回后该函数就会被执行
- C++与ABI
- 我们把符号修饰标准、变量内存布局、函数调用方式等这些跟可执行代码二进制兼容性相关的内容称为ABI(Application Binary Interface)
- C++一直为人诟病的一大原因是它的二进制兼容性不好
静态库链接
- 查看静态库
- 查看静态库包含的目标文件
$ ar -t libc.a
- 查看静态库中的函数
$ objdump -t libc.a
- 解压静态库
$ ar -x libc.a
- 查看静态库包含的目标文件
- 链接过程控制
- 链接过程控制一般有三种方法:(1) 命令行参数 (2) 将链接指令存放在目标文件里,比如
.drectve段 (3) 使用链接控制脚本 - Visual C++的控制脚本叫做模块定义文件,扩展名一般为.def
- 查看ld默认的链接控制脚本
$ ld -verbose
- 使用自己写的链接控制脚本
$ ld -T link.script
- 示例:最“小”的程序
- ld链接脚本语法简介P.128
- 链接过程控制一般有三种方法:(1) 命令行参数 (2) 将链接指令存放在目标文件里,比如
BFD库
- BFD库(Binary File Descriptor library)希望通过统一的接口来处理不同的目标文件格式
- ubuntu的BFD开发库在binutils-dev软件包中,可以通过apt安装
2.4 Windows平台的目标文件和可执行文件格式
Windows的二进制文件格式PE/COFF
- Windows平台上目标文件默认为COFF格式,而可执行文件为PE格式。很多时候我们可以将它们统称为PE/COFF文件
- PE/COFF文件中代码段一般叫
.code,数据段一般叫.data,不同编译器产生的目标文件的段名不同 - Visual C++中可以使用
#pragma将函数或变量放到自定义段 - Microsoft Visual C++编译环境
- 编译器
cl,链接器link,可执行文件查看器dumpbin - 查看目标文件结构:
dumpbin /ALL hello.obj > hello.txt
- 编译器
COFF文件结构
- COFF文件由文件头及后面的若干个段组成
- COFF文件头包括了两部分:一个是描述文件总体结构和属性的映像头(Image Header),另一个是描述文件中包含的段属性的段表(Section Table)
- 映像头是一个“IMAGE_FILE_HEADER”结构
- 段表是一个“IMAGE_SECTION_HEADER”结构
- COFF中代码段、数据段和BSS段的内容与ELF中几乎一样
- COFF中特有的两个段:
.drectve段(链接指示信息段)和.debug$S段(调试信息段)- 链接指示信息段保存的是编译器传递给链接器的命令行参数
.debug$S表示包含的是符号相关的调试信息段、.debug$P表示包含预编译头文件相关的调试信息段、.debug$T表示包含类型相关的调试信息段
- COFF符号表:主要包括符号名、符号的类型、所在的位置
PE文件结构
- PE文件是基于COFF的扩展,最主要的变化有两个
- 文件最开始的部分不是COFF文件头,而是DOS MZ可执行文件的文件头和桩代码
- 这个结构主要是为了兼容DOS文件格式而设计的
- 原来COFF文件头中的“IMAGE_FILE_HEADER”部分扩展成了PE文件文件头结构“IMAGE_NT_HEADERS”
- “IMAGE_NT_HEADERS”包含两个结构:映像头(Image Header)和PE扩展头部结构(Image Optional Header)
- 我们平时可以使用“IMAGE_OPTIONAL_HEADER”作为PE扩展头部结构的定义
- 文件最开始的部分不是COFF文件头,而是DOS MZ可执行文件的文件头和桩代码
- 数据目录(Data Directory)
- 为了方便很快地找到一些装载所需要的数据结构
- 数据目录在“IMAGE_OPTIONAL_HEADER”结构里面是“DataDirectory”成员,这个成员是一个“IMAGE_DATA_DIRECTORY”的结构数组
- 数据目录中包含了导入表、资源表、异常表、重定位表、调试信息表、线程私有存储等的地址和长度
第3部分 装载与动态链接
3.1 可执行文件的装载与进程
进程虚拟地址空间
- 每个程序被运行起来以后都将拥有自己独立的虚拟地址空间
- 以32位平台为例,Linux进程虚拟空间分布如图6-1所示
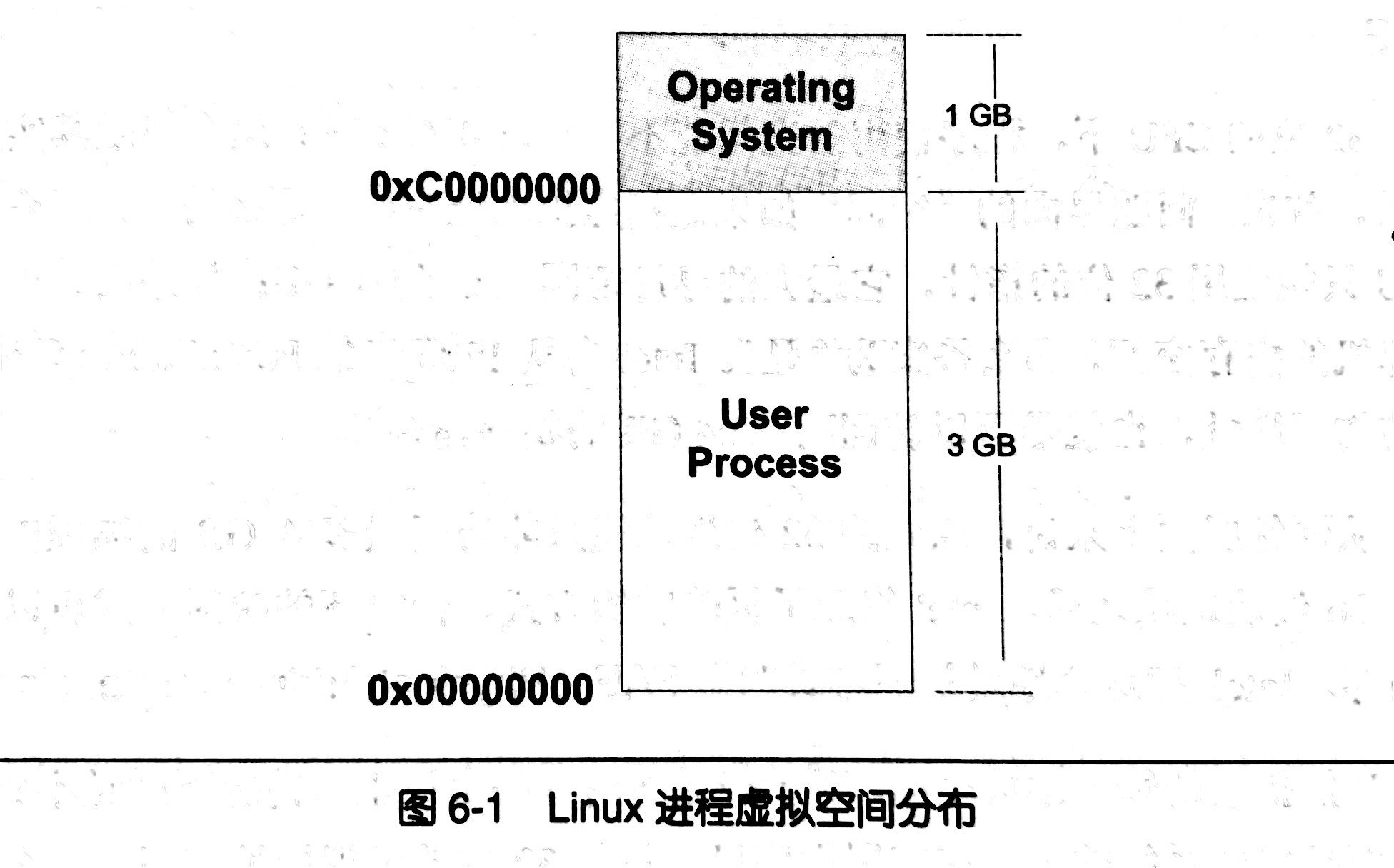
- 32位的地址线最多访问4GB物理内存,Intel采用PAE(Physical Address Extension)的地址扩展方式,扩展到36位地址线,最多可以访问高达64GB的物理内存
装载的方式
- 静态装入:将程序运行所需要的指令和数据全都装入内存中
- 动态装入:有覆盖装入(Overlay)和页映射(Paging)两种典型动态装载方法
- 覆盖装入:程序员手工将程序分割成若干块,由覆盖管理器来管理这些模块何时应该驻留内存而何时应该被替换掉
- 页映射
- 目前常用的页大小一般为4096字节
- 操作系统的存储管理器会决定什么时候装载页,空间不够的时候需要放弃哪些页
- 实现存储管理的算法有多种,常见的有FIFO先进先出算法和LUR最少使用算法等
可执行文件如何被操作系统装载
- 进程的建立:做了以下三件事情
- 创建一个独立的虚拟地址空间
- 读取可执行文件头,并且建立虚拟空间与可执行文件的映射关系
- Linux将进程虚拟空间中的一个段叫做虚拟内存区域(VMA, Virtual Memory Area),Windows将这个叫做虚拟段(Virtual Section)
- 将CPU的指令寄存器设置成可执行文件的入口地址,启动运行
- 页错误
- 随着进程的执行,页错误会不断产生,操作系统也会为进程分配相应的物理页面来满足进程执行的需求,如图6-6所示
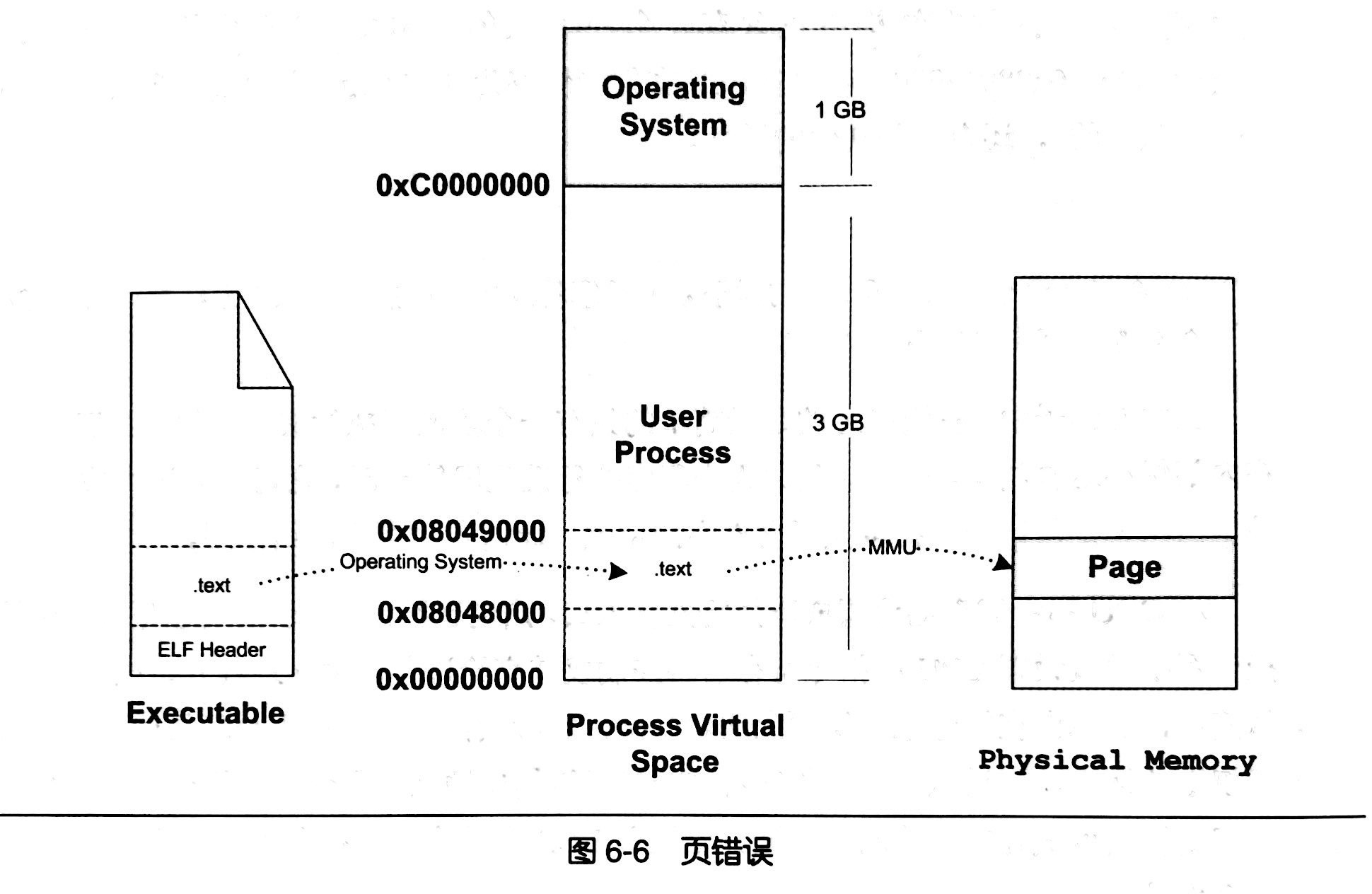
- 随着进程的执行,页错误会不断产生,操作系统也会为进程分配相应的物理页面来满足进程执行的需求,如图6-6所示
进程虚存空间分布
- ELF文件链接视图和执行视图
- 因为要以页大小为单位进行映射,如果将ELF文件中的每个段(Section)映射到内存中,会产生很多空间的浪费
- 操作系统加载可执行文件时最主要的只关心段的权限(可读、可写、可执行)
- 对于一个或多个相同权限的Sections,ELF可执行文件将它们合并成一个Segment进行映射
$ readelf -S a.out可以查看section段表(Section Header)$ readelf -l a.out可以查看Segment程序头(Program Header)- 从装载的角度看,我们一般只关心类型为“LOAD”的Segment
- 从Section的角度来看ELF文件就是链接视图(Linking View),从Segment的角度来看就是执行视图(Execution View)
- 堆和栈
$ cat /proc/[PID]/maps可以用来查看进程的虚拟空间分布- 输出结果的第二列是VMA的权限,r-可读、w-可写、x-可执行、p-私有、s-共享
- 输出结果的第四列是映像文件所在设备的主设备号和次设备号
- 如果主设备号和次设备号都是0,则表示VMA没有映射到文件中,这种VMA叫匿名虚拟内存区域(Anonymous Virtual Memory Area)
- heap–堆,stack–栈,vdso–内核模块
- 一个进程虚拟地址空间基本上可以分为代码VMA、数据VMA、堆VMA、栈VMA
- 堆的最大申请数量
- 段地址对齐
- 进程栈初始化
Linux内核装载ELF过程简介
- 装载过程
- 调用fork()创建一个新的进程
- 调用execve()系统调用
- 然后进入真正的装载工作
- 可执行文件的开头四个字节被称为魔数(Magic Number)
Windows PE的装载
- 32位PE文件中,段的起始地址和长度都是4096的整数倍
- PE可执行文件中段的数量一般很少,所以对齐到4096的整数倍浪费的空间相对于ELF文件比比较少
- 基地址:PE文件装载时的装载目标地址
- 相对虚拟地址(Relative Virtual Address):相对于基地址的相对地址